

Apple VSSFlow yapay zeka teknolojisi, sessiz videoları analiz ederek hem çevresel sesleri hem de insan konuşmalarını aynı anda üretebilen yeni bir dönemi başlatıyor.
Apple VSSFlow Yapay Zeka ile Ses Üretiminde Devrim
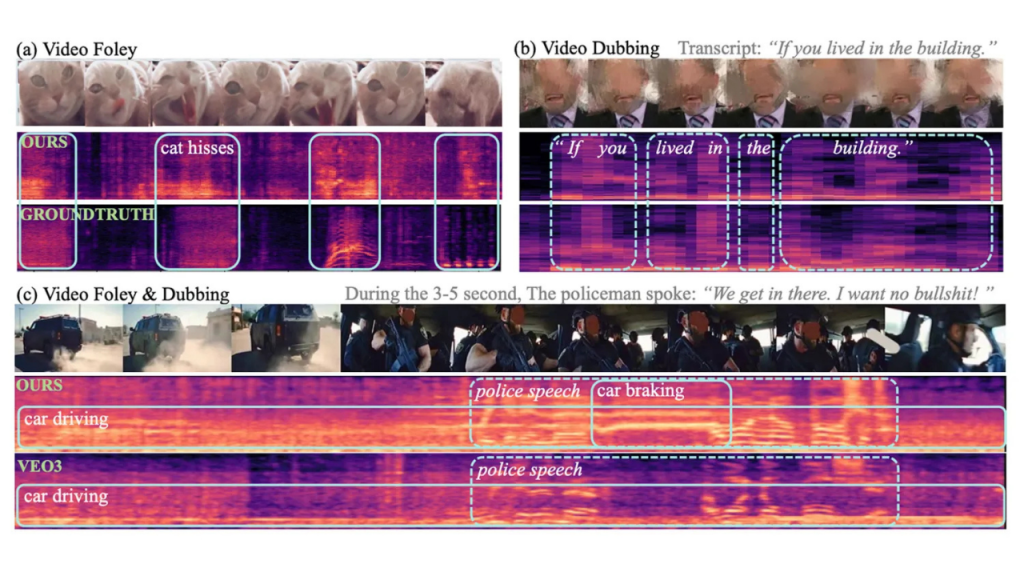
Apple araştırmacıları ve Çin Renmin Üniversitesi, sessiz videolardan ses ve konuşma üretebilen VSSFlow isimli yeni bir yapay zeka modeli geliştirdi. Mevcut modeller genellikle ya sadece çevresel sesleri ya da sadece metinden konuşmayı desteklerken, bu sistem her iki görevi tek bir potada eritiyor. Üstelik bu yeni mimari, ses ve konuşma eğitiminin birbirini engellemek yerine performansı artırdığını kanıtlıyor.
VSSFlow Teknolojisi Nasıl Çalışıyor?
Bu sistem, videoları analiz etmek için 10 katmanlı özel bir mimari kullanıyor. Görüntüleri saniyede 10 kare hızında tarayan model, videodaki görsel ipuçlarını takip ederek uygun ortam seslerini şekillendiriyor. Aynı zamanda videoya eşlik eden metin dökümleri sayesinde, karakterlerin ne söylediğini anlayarak son derece doğal konuşma sesleri oluşturabiliyor. Araştırmacılar, bu süreci gürültüden sinyal üretme prensibiyle çalışan “flow-matching” tekniğiyle optimize etti.
Karmaşık Sahnelerde Yüksek Başarı
VSSFlow, başlangıçta arka plan sesleri ile konuşmaları ayrı ayrı üretiyordu. Ancak geliştiriciler, modeli her iki ses türünün iç içe geçtiği sentetik verilerle eğiterek bu sorunu aştı. Yapılan testlerde, bu yeni sistemin sadece tek bir göreve odaklanan diğer modellerden daha yüksek performans sergilediği görüldü. Apple destekli bu projenin kodları GitHub üzerinden açık kaynak olarak paylaşılarak teknoloji dünyasının kullanımına sunuldu.


























{kind=link}